Llegamos al fin, en nuestra serie de posts dedicada al muestreo, al método estrella entre los muestreos no probabilísticos: el muestreo por cuotas. Esta técnica es la más habitual en investigación online a través de paneles. Podemos ver el muestreo por cuotas como la versión no probabilística del muestreo estratificado.
Fases de un muestreo por cuotas
El muestreo por cuotas consta de tres fases:
1. Segmentación
En primer lugar, dividimos la población objeto de estudio en grupos de forma exhaustiva (todos los individuos están en un grupo) y mutuamente exclusiva (un individuo sólo puede estar en un grupo), de forma similar a la división en estratos empleada en el muestreo estratificado. Normalmente esta segmentación se hace empleando alguna variable sociodemográfica como sexo, edad, región o clase social. Te explicamos un poco más abajo los criterios que deberías seguir para escoger qué variables usas para segmentar y fijar cuotas.
2. Fijamos el tamaño de las cuotas
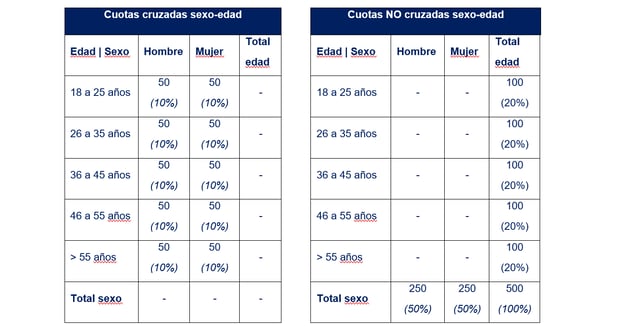
A continuación, fijamos el objetivo de individuos a encuestar para cada uno de estos grupos. Normalmente definiremos estos objetivos de forma proporcional al tamaño del grupo en la población. Por ejemplo, si hemos definido unos segmentos por sexo en una población en la que hay un 60% de mujeres y un 40% de hombres, y queremos obtener una muestra de 1.000 personas, definiremos un objetivo de 600 mujeres y 400 hombres. Estos objetivos se conocen como cuotas. En este ejemplo, tendríamos una cuota por sexo de 600 mujeres y 400 hombres. En ocasiones se definen cuotas no proporcionales a la población, por ejemplo para poder profundizar en el análisis de un grupo específico.
Te puede interesar: ¿Qué es una encuesta?, ¿Qué es una encuesta por muestreo? Usos en investigación
3. Selección de participantes y comprobación de cuotas
Por último, buscamos participantes para cubrir cada una de las cuotas definidas. En este punto es donde nos alejamos de un muestreo probabilístico. En el muestreo por cuotas aceptamos que la selección de individuos no sea aleatoria, puede ser una selección mediante muestreo por conveniencia. Por ejemplo, en un estudio en el que hayamos definido una cuota de 100 personas menores de 25 años y 100 personas de 25 o más años, podríamos salir a la calle y abordar a las personas que encontramos a nuestro paso, preguntarles su edad y encuestarlas si no hemos cubierto nuestro objetivo.
 De acuerdo a la descripción anterior, la diferencia entre el muestreo estratificado y el muestreo por cuotas está en la forma en que se seleccionan los participantes. En el muestreo estratificado disponemos de una lista completa de los individuos que forman el universo (es decir, los posibles entrevistados), todos ellos con una cierta probabilidad conocida de ser seleccionados. En el muestreo por cuotas no. Vamos obteniendo candidatos a formar parte de la muestra de forma no aleatoria y vamos comprobando antes de entrevistar si son válidos para el estudio (es decir, si pueden formar parte de una de las cuotas definidas o ya hemos excedido el objetivo). Cuando hay que descartar a un posible participante por efecto de una cuota (es la mujer 101 cuando nuestra cuota es de 100 mujeres), hablamos de un individuo descartado por ser quota-full.
De acuerdo a la descripción anterior, la diferencia entre el muestreo estratificado y el muestreo por cuotas está en la forma en que se seleccionan los participantes. En el muestreo estratificado disponemos de una lista completa de los individuos que forman el universo (es decir, los posibles entrevistados), todos ellos con una cierta probabilidad conocida de ser seleccionados. En el muestreo por cuotas no. Vamos obteniendo candidatos a formar parte de la muestra de forma no aleatoria y vamos comprobando antes de entrevistar si son válidos para el estudio (es decir, si pueden formar parte de una de las cuotas definidas o ya hemos excedido el objetivo). Cuando hay que descartar a un posible participante por efecto de una cuota (es la mujer 101 cuando nuestra cuota es de 100 mujeres), hablamos de un individuo descartado por ser quota-full.
La elección de variables
La pregunta que nos podemos plantear es: ¿qué variables escoger en un muestreo por cuotas? ¿cómo segmentamos la población? Esta cuestión es un factor clave en este técnica.
Para responder, pensemos en la finalidad de usar cuotas: lograr que la muestra sea lo más representativa posible del universo estudiado. La idea es la siguiente: aunque estemos seleccionando individuos para la muestra de forma no aleatoria, al menos garanticemos que dicha muestra guarda las mismas proporciones que el universo en relación a algunas variables, como sexo y edad. Pero, ¿por qué sexo y edad? ¿por qué no usar región? ¿o por qué no usar la altura y el peso de los individuos?
Las variables que usemos para definir cuotas en una muestra deberían cumplir dos condiciones:
(1) Que sean variables afectadas (es decir, sesgadas) por la forma no aleatoria en que seleccionamos individuos para la muestra. Por ejemplo, en una encuesta telefónica tendemos a encontrar personas de más edad que en una muestra aleatoria, y también un porcentaje elevado de personas en paro. Por lo tanto, debería añadir una cuota por edad y una por ocupación.
(2) Que sean variables que influyan en el dato que quiero medir. En un estudio electoral, podemos aceptar que sexo, edad y región influyen en la intención de voto. Por lo tanto, nos interesa añadir cuotas sobre estas variables.
Veamos los dos criterios anteriores en un ejemplo concreto. Supongamos que queremos medir a través de una muestra extraída de un panel online el tanto por ciento de personas que fuman en una población . ¿Qué variables deberíamos seleccionar para definir cuotas?
Siguiendo el primer criterio, seleccionaremos variables que puedan aparecer distorsionadas por el hecho de seleccionar a la muestra en un panel online respecto a la población general: por ejemplo la edad (en los paneles online suele haber mayor proporción de jóvenes) y la clase social (los paneles tienen dificultades para captar personas de clases bajas, especialmente en América Latina).
Podríamos prescindir de cuotas por región geográfica por un doble motivo. En primer lugar, los paneles online no suelen captar en una región concreta de un país, sino que captan a través de medios online que son accesibles desde cualquier región. Podríamos aceptar por lo tanto que la variable "región" no está afectada por la selección no aleatoria.
Si atendemos al segundo criterio (cuotas que puedan afectar al resultado medido), podríamos optar por añadir una cuota de sexo: el hábito de fumar suele variar entre hombres y mujeres y, salvo que trabajemos con un panel en el que nos garanticen que la composición por sexo es perfecta, es recomendable controlar esta cuota también.
Muestreo por cuotas y representatividad
El uso de cuotas en un muestreo no probabilístico no nos va a permitir transformarlo en probabilístico. Seguiremos sin poder calcular el margen de error y el nivel de confianza sobre los resultados. Es decir, el uso de cuotas no permite medir el grado de precisión de nuestros resultados. ¿Significa esto que es lo mismo usar o no usar cuotas? ¿Es el muestreo por conveniencia equivalente al muestreo por cuotas? La respuesta es NO. El uso de cuotas pone cierto control a los sesgos que pueden producirse por el método de selección empleado, nos garantiza que en una serie de variables clave vamos a reproducir la composición de la población en nuestra muestra. El problema es que, pese a que es una práctica común por parte de muchos investigadores, no vamos a poder afirmar cuán representativa es nuestra muestra. Las cuotas mejoran la representatividad, pero no sabemos cuánto.
¿Significa esto que es lo mismo usar o no usar cuotas? ¿Es el muestreo por conveniencia equivalente al muestreo por cuotas? La respuesta es NO. El uso de cuotas pone cierto control a los sesgos que pueden producirse por el método de selección empleado, nos garantiza que en una serie de variables clave vamos a reproducir la composición de la población en nuestra muestra. El problema es que, pese a que es una práctica común por parte de muchos investigadores, no vamos a poder afirmar cuán representativa es nuestra muestra. Las cuotas mejoran la representatividad, pero no sabemos cuánto.
Pese a todo, el muestreo por cuotas es uno de los métodos de muestreo más populares y prácticamente el único método viable cuando hacemos investigación online (salvo que contemos con un panel probabilístico). Usar cuotas es un sistema efectivo y económico de obtener muestras que proporcionan información relevante.
Ventajas e inconvenientes
La principal ventaja del muestreo por cuotas es que ofrece resultados útiles a un coste efectivo y, si se han elegido correctamente las variables sobre las que segmentar, dichos resultados suelen ser fiables. Y, a fin de cuentas, es con mucha diferencia el método no probabilístico que más similitudes guarda con los métodos probabilísticos.
Los principales inconvenientes son:
1. La imposibilidad de acotar el error que estamos cometiendo al usar este tipo de muestreo.
2. El riesgo de obviar una cuota relevante en un estudio. Por ejemplo, si en un estudio electoral no fijamos una cuota por regiones y resulta que la tendencia de voto es muy diferente en unas regiones respecto a otras, los resultados globales estarán fuertemente distorsionados. La elección de cuotas adecuadas requiere cierto conocimiento previo del investigador tanto del problema investigado como de la forma en que se obtienen participantes.
3. El coste del muestreo crece de forma exponencial a medida que añadimos más cuotas (variables a controlar) y más tramos en cada cuota (en un cuota de edad, por ejemplo, si definimos grupos de edad de 5 años necesitamos más tramos que si definimos grupos de edad de 20 años).
Errores frecuentes al usar cuotas en Internet
El muestreo por cuotas es una técnica muy popular. La mayor parte de estudios de mercado u opinión telefónicos y personales, ante la falta de un marco muestral preciso (como podría ser un censo de población) emplean cuotas para asegurar un nivel de representatividad aceptable. Esta técnica también predomina en estudios online a través de paneles. Sin embargo, el medio online tiene sus particularidades y es frecuente que algunos investigadores no las tengan en cuenta, limitándose a reproducir técnicas empleadas en medios offline. Esta práctica puede producir resultados de menor calidad y en algunos casos mayores costes.
A continuación te detallamos algunos ejemplos de diferencias en el uso de cuotas online y offline.
Cuotas geográficas
 En offline: la región del encuestado es una variable clave a controlar cuando se hacen encuestas personales, por razones obvias. Si los encuestadores están en una ciudad, todos los entrevistados serán de esa ciudad. Es por ello que la región es una cuota clave.
En offline: la región del encuestado es una variable clave a controlar cuando se hacen encuestas personales, por razones obvias. Si los encuestadores están en una ciudad, todos los entrevistados serán de esa ciudad. Es por ello que la región es una cuota clave.
Si la región está considerada como una variable irrelevante, se puede usar muestreo por conglomerados o una versión no probabilística similar. En este caso, la muestra se obtiene de unas cuantas ciudades, las más importantes de cada país, para reducir el coste.
En online: la región no es tan importante ya que es normal encontrar personas de diferentes ciudades en Internet sin incurrir en sobrecostes. Por ello, si el factor geográfico no es clave, podríamos no controlar las cuotas geográficas. En caso de que fuese importante, podríamos fijar cuotas para obtener respuesta de todas las regiones, no de unas pocas ciudades. De esta forma obtendríamos mejores datos y a menor coste, ya que podríamos usar todo el panel para obtener resultados.
Cuotas por clase social
En offline: la clase social no suele considerarse una cuota clave en países europeos y norteamericanos, o al menos no en todos los estudios. Las diferencias entre clases sociales existen pero no son tan profundas como en ciertas regiones latinoaméricanas, donde al recolectar los datos mediante entrevista personal, las clases sociales bajas son muy simples de obtener mientras que las altas son de difícil acceso.
En online: la clase social es más relevante que en offline, especialmente en países con una adopción de Internet media o baja. Curiosamente, en estos países la situación en Internet es inversa a la situación offline: es más fácil acceder a clases altas en Latinoamérica a través de Internet y es muy difícil acceder a clases bajas.
Cuotas por sexo y edad
En offline: sexo y edad son variable típicamente controladas mediante cuotas. En encuestas personales no suelen dar muchos problemas, mientras que en encuestas telefónicas es más sencillo acceder a mujeres que a hombres, y a personas mayores que a jóvenes. Con la irrupción del móvil el problema se ha agravado, ya que los jóvenes apenas usan el teléfono fijo.
En online: ambas variables deben controlarse, igual que en offline. Los paneles online acceden más fácilmente a gente joven, especialmente en la franja de los 20 a 35 años, pero tienen dificultades con adolescente y personas mayores. También es habitual que los paneles recluten más mujeres que hombres, porque son más demandadas para estudios de mercado, por lo que es necesario controlar la variable sexo.
Esperamos que este post os ayude a entender cómo obtener muestras no probabilísticas útiles. El muestreo por cuotas es fundamental en la investigación online. Os esperamos en el próximo post de esta serie, que dedicaremos a la técnica conocida como bola de nieve.
Conoce Nuestro Servicio de Muestreo Ad-hoc
En Netquest, entendemos la importancia de obtener datos precisos y representativos para tus investigaciones de mercado. Es por eso que te recomendamos el servicio de muestreo ad-hoc de Netquest, un líder confiable en el sector de investigación digital. Con su amplia experiencia y una vasta red de paneles online, Netquest ofrece soluciones a medida que se adaptan a las necesidades específicas de tu proyecto.
Para más información y para ver cómo pueden ayudarte a alcanzar tus objetivos de investigación, visita su página de servicios de muestreo ad-hoc.
ÍNDICE: Serie Muestreo
-
Muestreo no probabilístico: muestreo por cuotas