
En un post anterior vimos cómo podíamos acompañar los resultados de un estudio NPS (Net Promoter Score) con un intervalo de confianza. Los intervalos de confianza forman parte de una forma de entender la estadística, conocida como estadística Frecuentista. Pero hay una mirada alternativa, la estadística Bayesiana.
Hoy os proponemos resolver el mismo problema usando la estadística Bayesiana, empleando lo que se conoce como intervalos creíbles. Con este pretexto, trataremos de introducirte en los fundamente de una inferencia estadística siguiendo los principios Bayesianos.
Estadística frecuentista vs bayesiana
El concepto de probabilidad admite diversas interpretaciones. Durante el siglo XIX y XX la interpretación dominante fue la impuesta por la estadística Frecuentista, que asocia probabilidad a sucesos experimentales repetibles: lanzo un dado muchas veces, observo que las 6 caras del dado tienden a aparecer el mismo número de veces, asigno una probabilidad 1/6 a cada suceso.
Sin embargo, a finales del siglo XX resurgió una interpretación del concepto de probabilidad más amplio. Y digo “resurgió” porque la idea proviene del siglo XVIII, en concreto, del matemático británico Thomas Bayes. De ahí que esta interpretación forme parte de lo que se conoce como estadística Bayesiana. Bajo este paradigma, probabilidad es el grado de certeza que tenemos de que se producirá un suceso, sea experimental y repetible (como el lanzamiento de un dado) o no (el lanzamiento de un cohete o el tiempo que hará mañana).
Ambas formas de entender la probabilidad proponen miradas diferentes sobre los mismos problemas. Los intervalos de confianza que empleamos cuando estimamos parámetros de una población a través de una muestra, y que hemos visto numerosas veces en nuestro blog, forman parte de la estadística Frecuentista. Pero la estadística Bayesiana tiene su propia forma de atacar el mismo problema: los intervalos creíbles.
Inferencia bayesiana
Por si no estás familiarizado con la estadística Bayesiana, te resumimos las ideas básicas de una inferencia estadística usando este paradigma.
Supongamos que tenemos una población de la que queremos estimar unos parámetros H, por ejemplo, la edad media de los individuos que forman la población. Tomamos una muestra de n personas y observamos unos datos D de las mismas, por ejemplo, la edad de cada una de las personas que forman la muestra. Los datos D que observamos están obviamente condicionados por los parámetros H que queremos estimar: si la media poblacional de la edad es baja, es más probable que los sujetos de la muestra tengan una edad baja. Podemos reflejar este hecho indicando que la distribución de probabilidad de los datos observados es p(D|H), para reflejar que los datos están condicionados por los parámetros poblacionales (el símbolo | significa justamente eso, "condicionado a").
Pero lo que realmente nos interesa cuando hacemos una inferencia es la probabilidad condicionada inversa, es decir, responder a la pregunta siguiente: ¿qué probabilidad tienen los posibles valores de los parámetros H dados los datos D que observo? En otras palabras, queremos estimar p(H|D).
Aquí es donde entra en juego Bayes. Según su célebre teorema
Esta expresión utiliza dos probabilidades más además de p(D|H) y p(H|D), que son necesarias para realizar la inferencia:
- p(H) es la probabilidad de observar los diferentes valores de los parámetros H con independencia de los datos observados. O, puedes verlo así: antes de haber visto los datos observados. Por ello esta expresión se conoce como probabilidad a priori. En contrapartida, la probabilidad que queremos calcular, p(H|D), se conoce como la probabilidad a posteriori, una vez ya hemos visto los datos.
- p(D) es la probabilidad de observar diferentes datos para todos los posibles valores de H. En otras palabras, puede calcularse como la integral del numerador de esta expresión sobre todos los posibles valores de H
En la práctica, p(D) no es muy relevante en esta ecuación: no depende de H y la podemos tratar como una constante de normalización que garantiza que p(H|D) es una probabilidad y, por tanto, todos sus posibles valores suman 1. Es por ello que muy a menudo la inferencia Bayesiana se expresa como
donde el símbolo α indica “proporcional a”. Es decir, la “probabilidad a posteriori” es proporcional a “la probabilidad a priori” por p(D|H), conocida como “verosimilitud”. Veremos luego la utilidad de esta expresión.
Observa que en una inferencia Bayesiana no estimamos un valor concreto del parámetro H. Tampoco un intervalo de valores entre los que el valor H se encuentra con cierta probabilidad. Lo que estimamos es p(H|D), la distribución de probabilidad completa de los posibles valores de H una vez hemos observado los datos D. Una vez tenemos esta distribución, es posible ofrecer un intervalo con los valores más probables, algo que se denomina intervalo creíble para diferenciarlo del intervalo de confianza Frecuentista.
Un NPS bayesiano
Vamos a tratar de aplicar el enfoque Bayesiano al problema del NPS. En primer lugar, tenemos que identificar qué parámetros queremos estimar, qué datos observamos y cómo se relacionan unos con otros.
Para ello, pensemos en la población que tenemos entre manos: una población de clientes, cada uno de ellos con una opinión respecto a nuestro servicio o producto. Estas opiniones las tenemos clasificadas en 3 posibles categorías: promotores (+1), detractores (-1) y neutros (0). Esto define una distribución de probabilidad discreta en cuanto a la opinión de la población con 3 posibles valores. De esta distribución es de donde extraemos nuestra muestra, según el esquema siguiente.
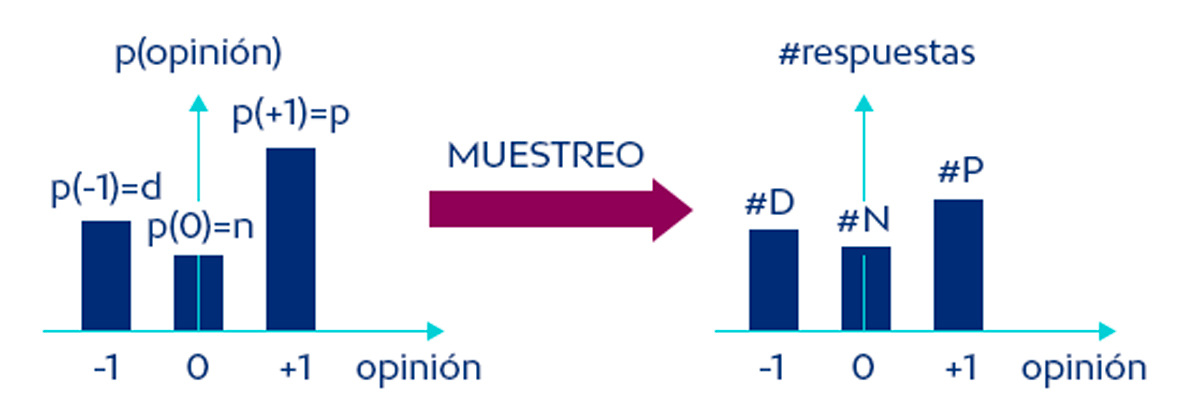
Los datos D que observamos son, por lo tanto, el recuento de promotores (#P), detractores (#D) y neutros (#N) de una muestra, el gráfico de la derecha. Y a través de ellos, queremos describir la distribución de probabilidad de la población de la que proviene la muestra, el gráfico de la izquierda.
Esta distribución tiene 3 posibles valores (-1,0,1), cada uno con una probabilidad p(-1), p(0) y p(1). Pero estas 3 probabilidades en realidad solo requieren 2 parámetros para estar totalmente definidas, ya que sabemos que deben sumar uno: p(-1) + p(0) + p(1) = 1.
Por ello, definimos como parámetros a estimar.
- La probabilidad de ser promotor: p(1) o para abreviar simplemente p.
- La probabilidad de ser detractor: p(-1), para abreviar d.
Si estimamos estos dos valores, la probabilidad de ser neutro ya está definida y es 1-p-d. Observa que el NPS poblacional, lo que realmente queremos estimar, también está definido por p y d, en concreto, NPS=p-d.
Los datos que observamos (#P, #D y #N) dependen de esta distribución de probabilidad de la población, pero, lógicamente, al tratarse de una muestra, las proporciones de promotores, detractores y neutros en la muestra pueden desviarse de las probabilidades de cada categoría en la población.
Función de verosimilitud
Recuperemos la fórmula central de la inferencia Bayesiana
Podemos reescribirla para nuestro problema particular, sabiendo cuáles son los parámetros poblacionales a estimar y los datos que observamos
La expresión p(#P,#D,#N|p,d), conocida como función de verosimilitud o likelihood function, expresa cuán probable es que observemos los datos que tenemos para unos valores concretos de p y d. Es algo que podemos expresar matemáticamente sabiendo que:
- Cada participante en la encuesta NPS puede considerarse una observación independiente extraída de la misma distribución de probabilidad.
- La probabilidad de observar n observaciones independientes a la vez es el producto de las probabilidades de cada una de las observaciones.
- Las probabilidades de observar un promotor, un detractor y un neutro, son p, d y 1-p-d.
Uniendo estos elementos
Recuerda que la función de verosimilitud es una función de los parámetros poblacionales, en este caso de p y d, ya que el recuento de opiniones en la encuesta #P, #D y #N son datos conocidos.
Distribución a priori
Nos falta definir la distribución a priori de los parámetros p y d. Este siempre es un punto polémico en la inferencia Bayesiana, que no tiene su contrapartida en la inferencia Frecuentista.
La opción más simple y conservadora es considerar que todos los valores de p y d son equiprobables. Sabiendo que p y d son probabilidades, esto nos definiría una distribución uniforme en un espacio bidimensional comprendido entre los valores 0≤p≤1 y 0≤d≤1.
Esto puede afinarse un poco: en realidad, p y d no pueden tomar cualquier valor entre 0 y 1, independientemente uno de otro. Forman parte de una distribución de 3 valores que debe sumar 1. Si el 100% de la población son promotores, seguro que tenemos 0% de detractores y viceversa. Por lo tanto, los valores posibles de p y d se encuentran en una región definida por 0≤p≤1, 0≤d≤1 y p+d≤1. Esto configura un espacio triangular con probabilidad uniforme que podemos representar con la función U(0≤p≤1, 0≤d≤1, p+d≤1) y que tendría un aspecto como el siguiente.
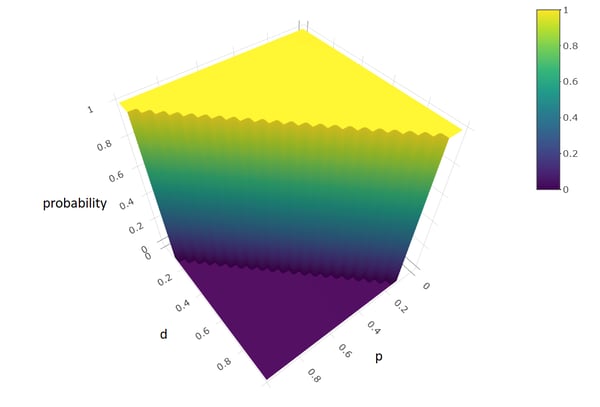
La estadística Bayesiana permite ir más allá. Si tenemos evidencias de estudios anteriores que nos hacen creer que hay ciertos valores más probables que otros en los parámetros p y d, podemos añadir esta información en la distribución a priori. Por ejemplo, podemos fijar que es imposible tener menos de 20% de promotores, o que los valores más probables son los que contemplan valores de p y d similares…
Probabilidad a posteriori
Ya tenemos definidos los elementos necesarios para realizar nuestra inferencia. La distribución a posteriori que buscamos es el producto de la distribución a priori por la función de verosimilitud, convenientemente normalizada.
Empezaremos usando la distribución a priori uniforme que hemos visto anteriormente:
Si quisiéramos tener una expresión cerrada para la probabilidad a posteriori, necesitaríamos calcular el denominador de la expresión anterior. Este denominador es la integral sobre todos los posibles valores de p y d del numerador.
Y aquí nos enfrentaríamos a un nuevo problema: la integral del denominador es muy compleja y no tiene una expresión analítica simple. Es un problema habitual de la inferencia Bayesiana y que durante años impidió su desarrollo.
Para resolver este problema, podemos recurrir a la simulación. Los métodos Monte Carlo basados en Cadenas de Markov permiten obtener muestras de una distribución de probabilidad cuando el muestreo directo es dificultoso, como en este caso.
En concreto, el algoritmo Metropolis-Hastings permite cumplir este objetivo a partir de una función proporcional a la densidad de probabilidad, sin necesidad de tener una expresión exacta de dicha densidad. Justo la situación en la que nos encontramos, puesto que
No vamos a explicar el algoritmo, pero te facilitamos un código en R comentado que permite ejecutarlo y te damos una idea intuitiva de qué hace.
|
#Posterior probability density simulation for a NPS study #Observed Data P<-200 #Promoters D<-100 #Detractors N<-200 #Neutrals
#Prior function, uniform in 0<=p<=1 and 0<=d<=1 and p+d<=1 uniformPrior <- function(param) { return ((0<=param[1]) && (param[1]<=1) && (0<=param[2]) && (param[2]<=1) && (param[1] + param[2] <= 1)) }
#Target function, proportional to posterior probability function targetlog <- function(param) { # p = param[1] d = param[2] #If param is out of the uniform prior region, return prob=0 if (!uniformPrior(param)) return(log(0)) #Calculate the likelihood return (P*log(param[1]) + D*log(param[2]) + N*log(1-param[1]-param[2])) }
#Simulation parameters burnout <- 1000 #discarded initial simulations simulations <- 10000 initial <- c(0.2,0.2) x<-matrix(0,nrow=burnout+simulations,ncol=2) x[1,]<-initial
#Simulate for (i in 2:nrow(x)) { #Propose a new x value, starting from the previous xnew<-rnorm(2,mean=x[i-1,],sd=0.1) #Calculate the ratio of probabilities (in log scale) alfa <- exp(targetlog(xnew) - targetlog(x[i-1,])) #Accept/Reject if (runif(1)<alfa) { x[i,]<-xnew } else { x[i,]<-x[i-1,] } }
#Separate simulations of p and d p<-x[(burnout+1):nrow(x),1] d<-x[(burnout+1):nrow(x),2] NPS<-p-d
#Density estimations plot(density(p)) plot(density(d)) plot(density(NPS))
#Calculate 90% intervals low <- 0.05*simulations high <- 0.95*simulations p <- p[order(p)] d <- d[order(d)] NPS <- NPS[order(NPS)]
pinterval <- c(p[low],p[high]) dinterval <- c(d[low],d[high]) NPSinterval <- c(NPS[low],NPS[high])
pinterval dinterval NPSinterval |
¿Qué es lo que hace este algoritmo? Básicamente lo siguiente:
- Toma un valor inicial de los parámetros p y d (0.2,0.2).
- Propone un nuevo valor de forma aleatoria desplazándose desde el valor inicial una cantidad arbitraria.
- Compara la probabilidad de uno y otro valor de acuerdo a nuestra distribución objetivo. Esta comparación la podemos hacer si tenemos una función proporcional a la distribución real, sin necesidad de tener una expresión exacta.
- Si el nuevo valor es más probable que el anterior, lo acepta y forma parte de la simulación. Si es menos probable, decide aleatoriamente si aceptarlo o rechazarlo. En concreto, obtiene un número aleatorio y lo compara con la proporción de probabilidades.
- Si lo rechaza, repite el valor anterior.
Este proceso produce secuencias que siguen la función de probabilidad deseada.
Repetimos el proceso 10,000 veces para tener una secuencia de valores simulados suficientemente larga. Una vez tenemos una secuencia de valores simulados de la distribución a posteriori de p y d podemos:
- Aproximar las densidades de probabilidad de p y de q.
- Estimar la densidad de probabilidad del valor NPS, calculando para ello la diferencia entre los valores simulados de p y q.
- Calcular un intervalo creíble para el valor NPS, nuestro objetivo final.
Si tratas de interpretar el algoritmo, ten en cuenta que el producto de probabilidades se calcula en escala logarítmica para evitar problemas de precisión propios de probabilidades muy pequeñas.
Ejemplo
Supongamos que hemos hecho un estudio NPS a 500 personas y hemos obtenido #P=200 promotores, #D=100 detractores y #N=200 neutros. El valor NPS en la muestra es por tanto NPS=200/500 – 100/500=0.2. Pero usando nuestro programa en R, podemos ir más allá.
Usando el algoritmo Metropolis-Hastings con 10,000 simulaciones, obtenemos una estimación de la densidad de probabilidad conjunta de p y d. Esta densidad muestra qué valores de estos parámetros son los más probables. También permite delimitar, por tanto, una región de alta probabilidad en la que esperamos encontrar estos parámetros.
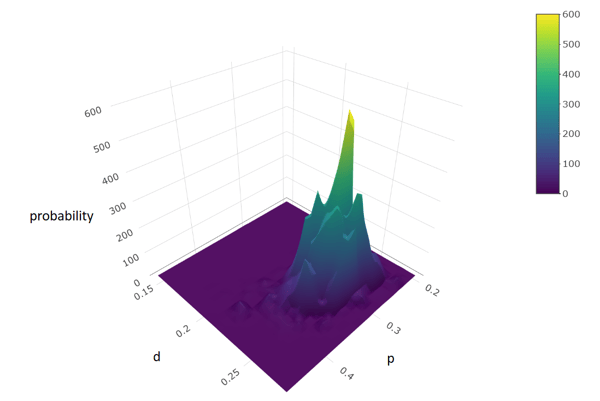
Para poder verlo con más claridad, podemos estimar las densidades de cada parámetro por separado: de p y d, y también del NPS resultante.
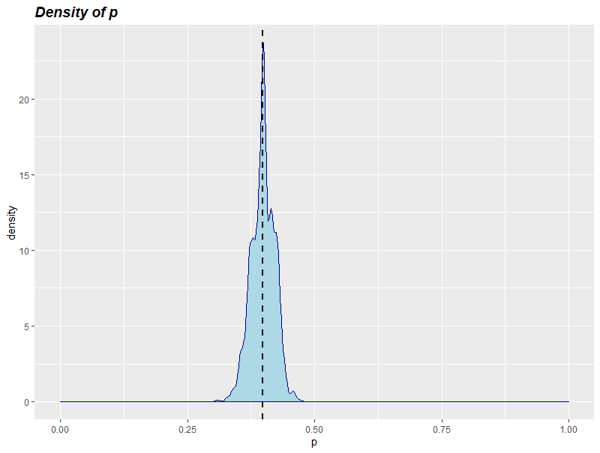
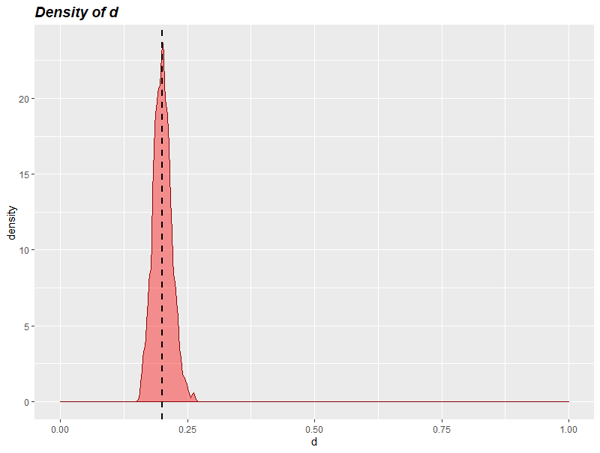
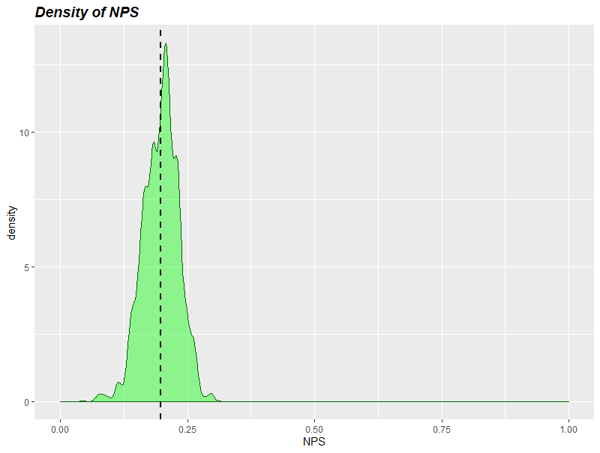 Para el valor del NPS, que es realmente el que nos interesa, podemos calcular qué intervalo de valores garantiza un 90% de cobertura, el intervalo creíble de valores. Resulta
Para el valor del NPS, que es realmente el que nos interesa, podemos calcular qué intervalo de valores garantiza un 90% de cobertura, el intervalo creíble de valores. Resulta
NPS = [14.7% <-> 25.3%] con probabilidad 90%
Este resultado se parece mucho al intervalo de confianza que obtuvimos en el post dedicado a la inferencia Frecuentista: 20% +- 5.5% = [14.5% <-> 25.5%]. Sin embargo, su significado es algo diferente.
Si hubiésemos obtenido este resultado con 50 encuestas solamente, manteniendo las mismas proporciones, la densidad de probabilidad del NPS estimado y el intervalo creíble habrían sido.
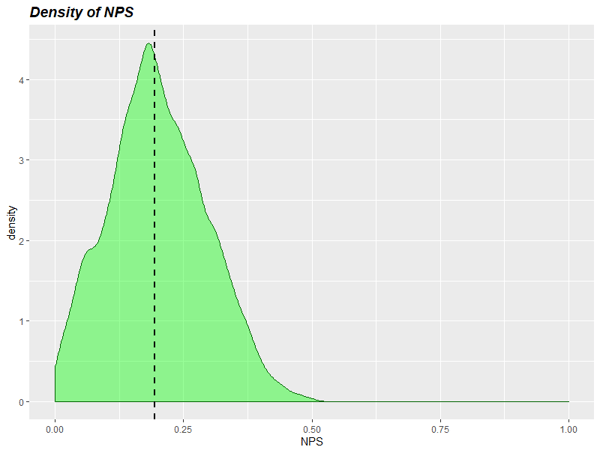
NPS = [1.9% <-> 35.3%] con probabilidad 90%
Ejemplo 2: usando información a priori
Imaginemos que el estudio del ejemplo 1 (con solo 50 encuestas), lo hacemos cada año. Y por nuestra experiencia, sabemos que el porcentaje de promotores y detractores nunca alcanza el 50% ni se queda por debajo del 10%. Podríamos hacer nuestra inferencia usando una distribución a priori acotada a este espacio: 0.1≤p,d≤0.5 y p+d≤1.
Si lo hacemos así, la inferencia resulta
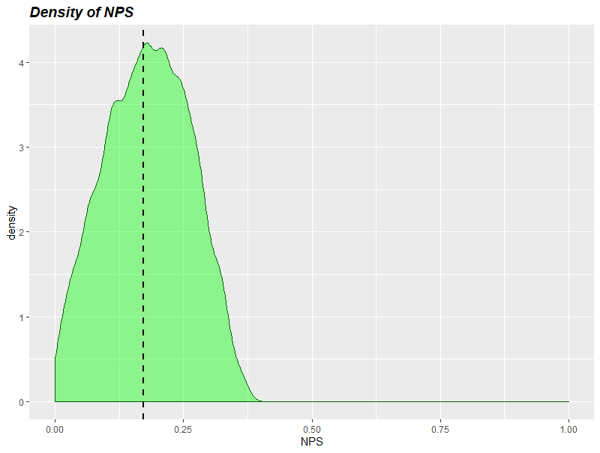
NPS = [1.4% <-> 31.5%] con probabilidad 90%.
Es decir, gracias a la información a priori hemos podido reducir algo el límite superior de nuestro intervalo (de 35.3% a 31.5%).
Ejemplo 3: información a priori de otro estudio
Supongamos ahora que hemos hecho un estudio preliminar sobre 30 individuos y hemos obtenido #P’=10 promotores, #D’=10 detractores y #N’=10 neutros. Queremos usar estos datos como información a priori de nuestro nuevo estudio hecho con solo 50 encuestados.
Éste es un caso muy conveniente para el análisis. Podemos pensar este caso así:
- El estudio preliminar lo hacemos usando una distribución a priori uniforme.
- El segundo estudio, usa como distribución a priori la distribución a posteriori del primer estudio. Y podríamos seguir encadenando inferencias una tras otra.
Al hacer eso, es posible demostrar que
Es decir, las observaciones del estudio preliminar se suman a las del segundo estudio. Esto es una propiedad muy útil de la inferencia Bayesiana: podemos ir agregando información a medida que la recibimos.
Al usar estas 30 respuestas adicionales, la estimación NPS hecha con 50 respuestas pasa de
NPS = [1.4% <-> 31.5%] con probabilidad 90%.
a
NPS = [0% <-> 25.9%] con probabilidad 90%.
La información a priori ha desplazado y reducido nuestro intervalo de confianza. Si fuésemos añadiendo más datos observados, la información a priori pasaría a ser irrelevante. Pero cuando tenemos pocos datos, esta información a priori puede ayudarnos a hacer una estimación más razonable.
Conclusión
La estadística Bayesiana puede ser un poco intimidatoria al principio. Nos da mucha más libertad, pero nos obliga a salirnos de los métodos prediseñados para resolver problemas específicos propios de la estadística Frecuentista. A cambio, nos permite crear nuestros propios modelos y añadir toda la información que tenemos a nuestro alcance para dar forma a una inferencia más realista.
La aplicación de esta forma de ver la estadística a un estudio NPS es relativamente simple. Una buena manera de empezar a pensar de forma Bayesiana.



